 Credit: Dreamstime
Credit: Dreamstime
For most professional software developers, using application lifecycle management (ALM) is a given. Data scientists, many of whom do not have a software development background, often have not used lifecycle management for their machine learning models. That’s a problem that’s much easier to fix now than it was a few years ago, thanks to the advent of “MLops” environments and frameworks that support machine learning lifecycle management.
What is machine learning lifecycle management?
The easy answer to this question would be that machine learning lifecycle management is the same as ALM, but that would also be wrong. That’s because the lifecycle of a machine learning model is different from the software development lifecycle (SDLC) in a number of ways.
To begin with, software developers more or less know what they are trying to build before they write the code. There may be a fixed overall specification (waterfall model) or not (agile development), but at any given moment a software developer is trying to build, test, and debug a feature that can be described. Software developers can also write tests that make sure that the feature behaves as designed.
By contrast, a data scientist builds models by doing experiments in which an optimization algorithm tries to find the best set of weights to explain a dataset. There are many kinds of models, and currently the only way to determine which is best is to try them all. There are also several possible criteria for model “goodness,” and no real equivalent to software tests.
Unfortunately, some of the best models (deep neural networks, for example) take a long time to train, which is why accelerators such as GPUs, TPUs, and FPGAs have become important to data science. In addition, a great deal of effort often goes into cleaning the data and engineering the best set of features from the original observations, in order to make the models work as well as possible.
Keeping track of hundreds of experiments and dozens of feature sets isn’t easy, even when you are using a fixed dataset. In real life, it’s even worse: Data often drifts over time, so the model needs to be tuned periodically.
There are several different paradigms for the machine learning lifecycle. Often, they start with ideation, continue with data acquisition and exploratory data analysis, move from there to R&D (those hundreds of experiments) and validation, and finally to deployment and monitoring. Monitoring may periodically send you back to step one to try different models and features or to update your training dataset. In fact, any of the steps in the lifecycle can send you back to an earlier step.
Machine learning lifecycle management systems try to rank and keep track of all your experiments over time. In the most useful implementations, the management system also integrates with deployment and monitoring.
Machine learning lifecycle management products
We’ve identified several cloud platforms and frameworks for managing the machine learning lifecycle. These currently include Algorithmia, Amazon SageMaker, Azure Machine Learning, Domino Data Lab, the Google Cloud AI Platform, HPE Ezmeral ML Ops, Metaflow, MLflow, Paperspace, and Seldon.
Algorithmia
Algorithmia can connect to, deploy, manage, and scale your machine learning portfolio. Depending on which plan you choose, Algorithmia can run on its own cloud, on your premises, on VMware, or on a public cloud. It can maintain models in its own Git repository or on GitHub. It manages model versioning automatically, can implement pipelining, and can run and scale models on-demand (serverless) using CPUs and GPUs. Algorithmia provides a keyworded library of models (see screenshot below) in addition to hosting your models. It does not currently offer much support for model training.
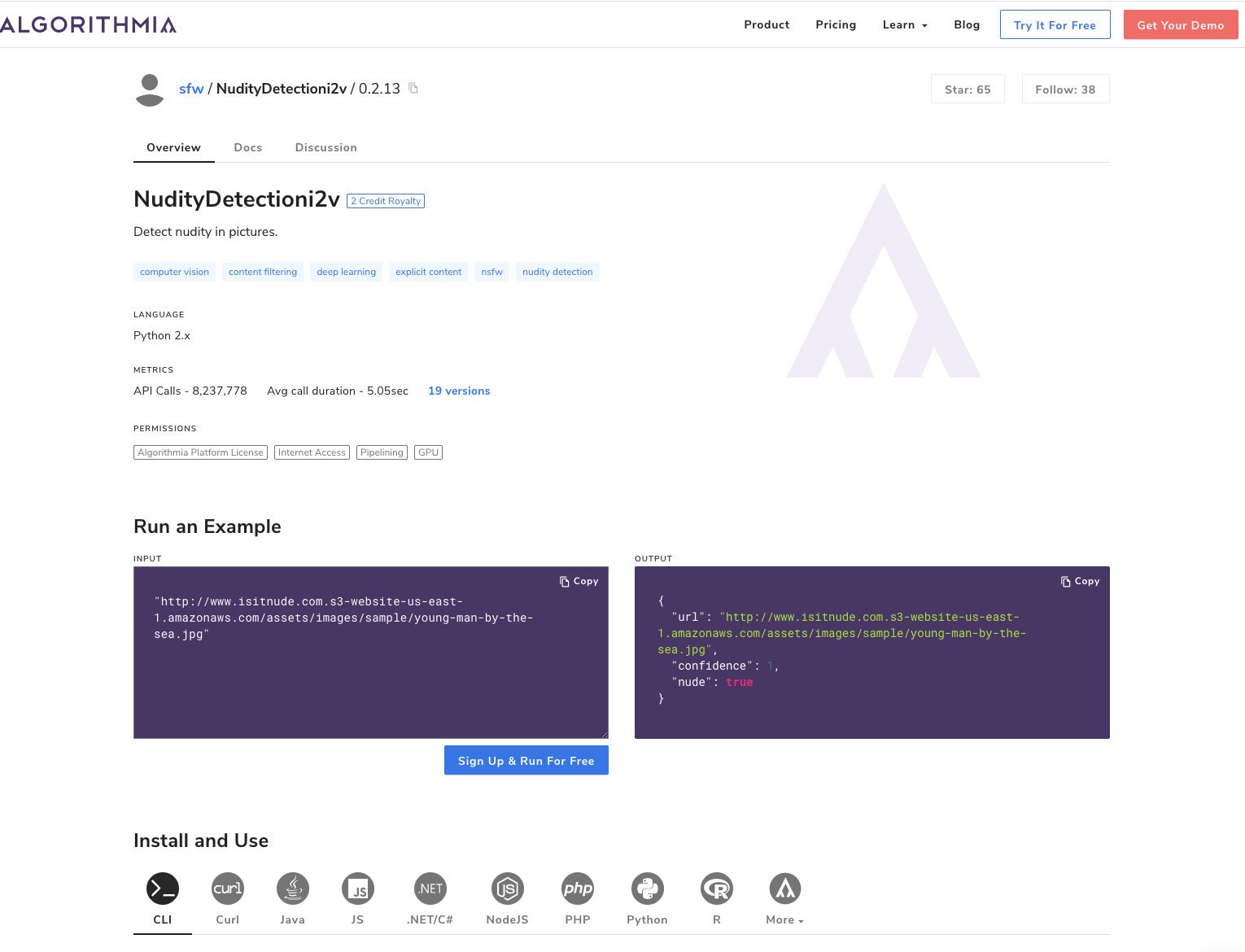 IDG
IDGAmazon SageMaker
Amazon SageMaker is Amazon’s fully managed integrated environment for machine learning and deep learning. It includes a Studio environment that combines Jupyter notebooks with experiment management and tracking (see screenshot below), a model debugger, an “autopilot” for users without machine learning knowledge, batch transforms, a model monitor, and deployment with elastic inference.
 IDG
IDGAzure Machine Learning
Azure Machine Learning is a cloud-based environment that you can use to train, deploy, automate, manage, and track machine learning models. It can be used for any kind of machine learning, from classical machine learning to deep learning, and both supervised learning and unsupervised learning.
Azure Machine Learning supports writing Python or R code as well as providing a drag-and-drop visual designer and an AutoML option. You can build, train, and track highly accurate machine learning and deep-learning models in an Azure Machine Learning Workspace, whether you train on your local machine or in the Azure cloud.
Azure Machine Learning interoperates with popular open source tools, such as PyTorch, TensorFlow, Scikit-learn, Git, and the MLflow platform to manage the machine learning lifecycle. It also has its own open source MLOps environment, shown in the screenshot below.
 IDG
IDGDomino Data Lab
The Domino Data Science platform automates devops for data science, so you can spend more time doing research and test more ideas faster. Automatic tracking of work enables reproducibility, reusability, and collaboration. Domino lets you use your favorite tools on the infrastructure of your choice (by default, AWS), track experiments, reproduce and compare results (see screenshot below), and find, discuss, and re-use work in one place.
 IDG
IDGGoogle Cloud AI Platform
The Google Cloud AI Platform includes a variety of functions that support machine learning lifecycle management: an overall dashboard, the AI Hub (see screenshot below), data labeling, notebooks, jobs, workflow orchestration (currently in a pre-release state), and models. Once you have a model you like, you can deploy it to make predictions.
The notebooks are integrated with Google Colab, where you can run them for free. The AI Hub includes a number of public resources including Kubeflow pipelines, notebooks, services, TensorFlow modules, VM images, trained models, and technical guides. Public data resources are available for image, text, audio, video, and other types of data.
 IDG
IDGHPE Ezmeral ML Ops
HPE Ezmeral ML Ops offers operational machine learning at enterprise scale using containers. It supports the machine learning lifecycle from sandbox experimentation with machine learning and deep learning frameworks, to model training on containerized distributed clusters, to deploying and tracking models in production. You can run the HPE Ezmeral ML Ops software on-premises on any infrastructure, on multiple public clouds (including AWS, Azure, and GCP), or in a hybrid model.
Metaflow
Metaflow is a Python-friendly, code-based workflow system specialized for machine learning lifecycle management. It dispenses with the graphical user interfaces you see in most of the other products listed here, in favor of decorators such as @step, as shown in the code excerpt below. Metaflow helps you to design your workflow as a directed acyclic graph (DAG), run it at scale, and deploy it to production. It versions and tracks all your experiments and data automatically. Metaflow was recently open-sourced by Netflix and AWS. It can integrate with Amazon SageMaker, Python-based machine learning and deep learning libraries, and big data systems.
from metaflow import FlowSpec, step
class BranchFlow(FlowSpec):
@step
def start(self):
self.next(self.a, self.b)
@step
def a(self):
self.x = 1
self.next(self.join)
@step
def b(self):
self.x = 2
self.next(self.join)
@step
def join(self, inputs):
print('a is %s' % inputs.a.x)
print('b is %s' % inputs.b.x)
print('total is %d' % sum(input.x for input in inputs))
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
BranchFlow()MLflow
MLflow is an open source machine learning lifecycle management platform from Databricks, still currently in Alpha. There is also a hosted MLflow service. MLflow has three components, covering tracking, projects, and models.
MLflow tracking lets you record (using API calls) and query experiments: code, data, config, and results. It has a web interface (shown in the screenshot below) for queries.
MLflow projects provide a format for packaging data science code in a reusable and reproducible way, based primarily on conventions. In addition, the Projects component includes an API and command-line tools for running projects, making it possible to chain together projects into workflows.
MLflow models use a standard format for packaging machine learning models that can be used in a variety of downstream tools — for example, real-time serving through a REST API or batch inference on Apache Spark. The format defines a convention that lets you save a model in different “flavors” that can be understood by different downstream tools.
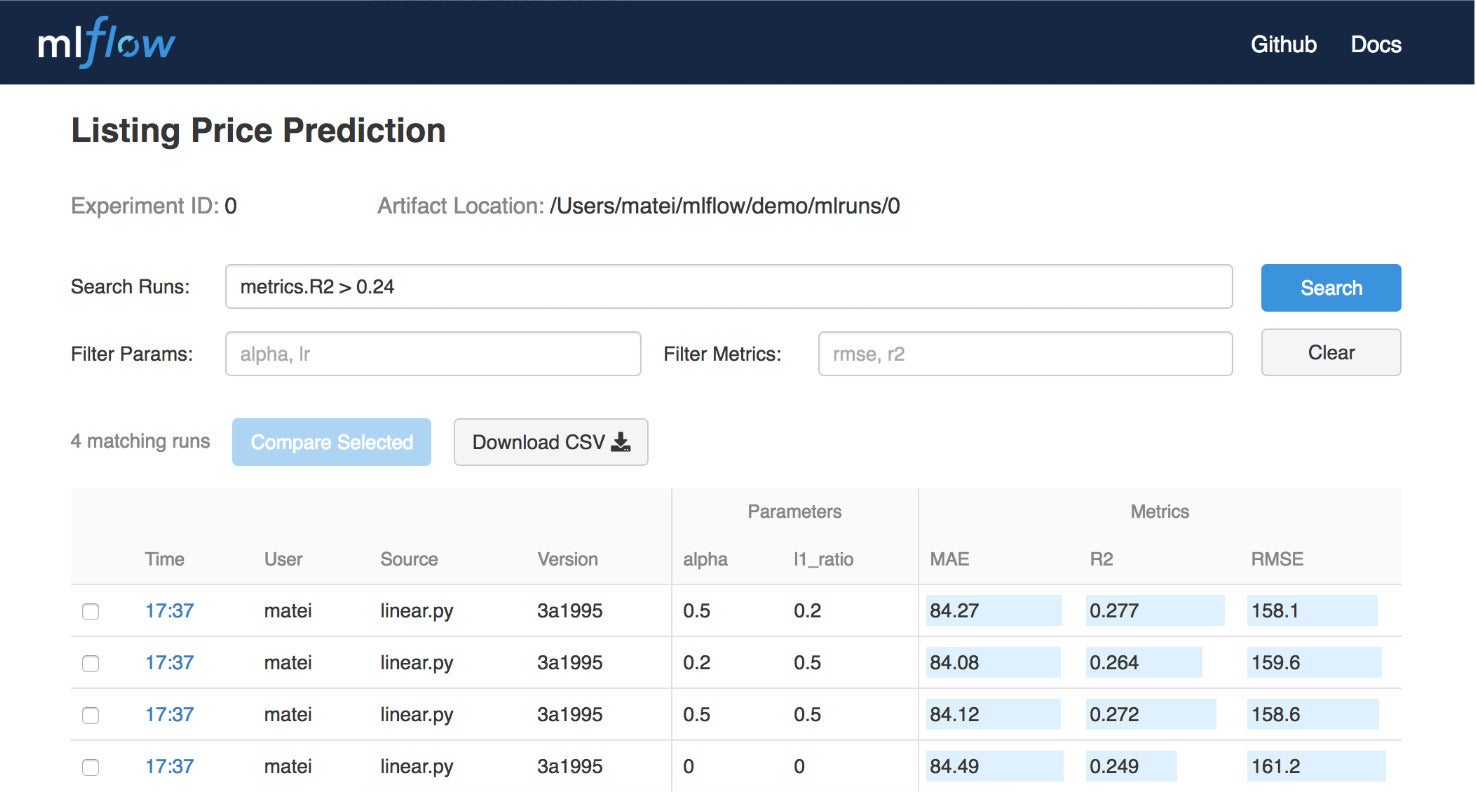 IDG
IDGPaperspace
Paperspace Gradientº is a suite of tools for exploring data, training neural networks, and building production-grade machine learning pipelines. It has a cloud-hosted web UI for managing your projects, data, users, and account; a CLI for executing jobs from Windows, Mac, or Linux; and an SDK to programmatically interact with the Gradientº platform.
Gradientº organizes your machine learning work into projects, which are collections of experiments, jobs, artifacts, and models. Projects can optionally be integrated with a GitHub repo via the GradientCI GitHub app. Gradientº supports Jupyter and JupyterLab notebooks.
Experiments (see screenshot below) are designed for executing code (such as training a deep neural network) on a CPU and optional GPU without managing any infrastructure. Experiments are used to create and start either a single job or multiple jobs (e.g. for a hyperparameter search or distributed training). Jobs are a made up of a collection of code, data, and a container that are packaged together and remotely executed. Paperspace experiments can generate machine learning models, which can be interpreted and stored in the Gradient Model Repository.
Paperspace Core can manage virtual machines with CPUs and optionally GPUs, running in Paperspace’s own cloud or on AWS. Gradientº jobs can run on these VMs.
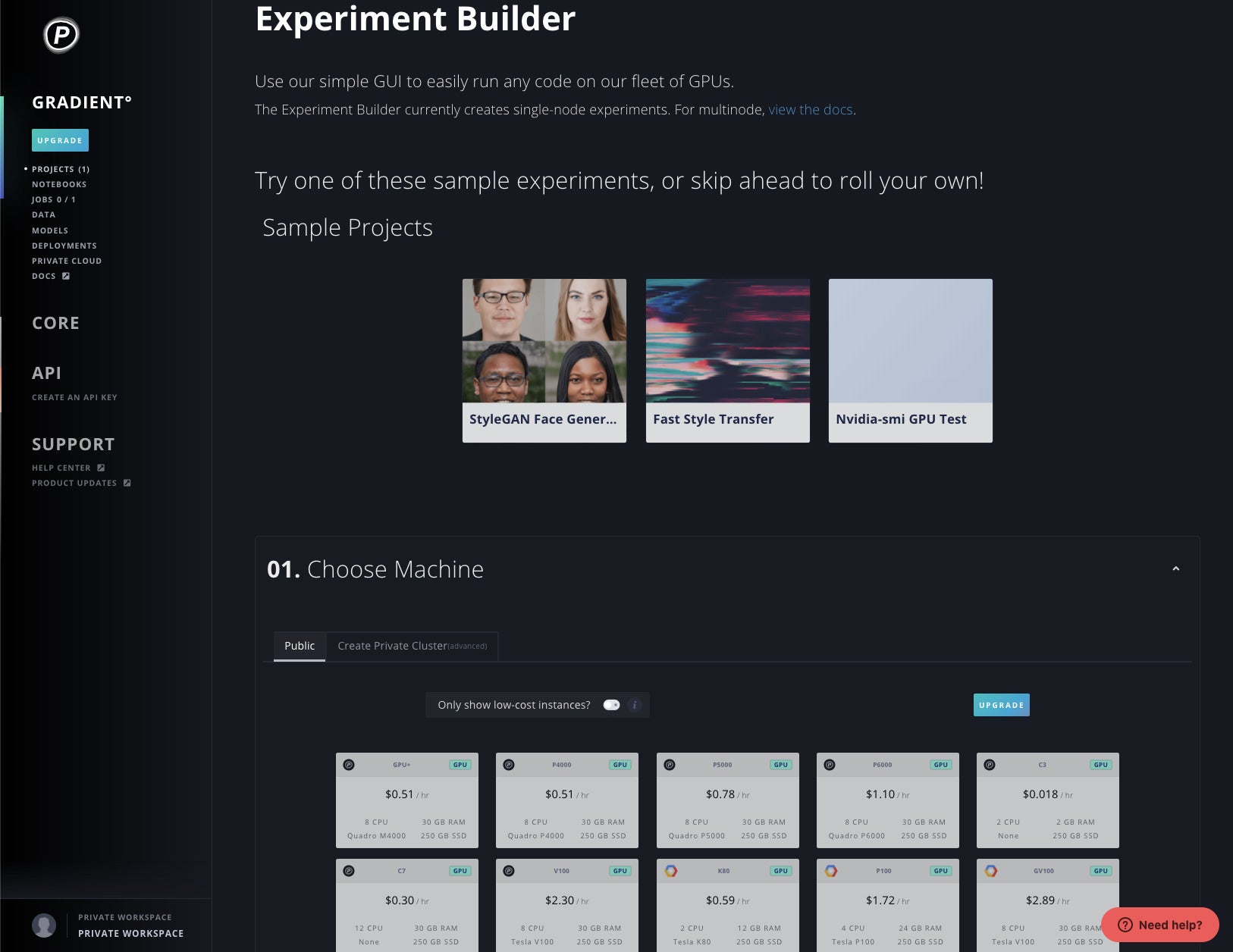 IDG
IDGSeldon
Seldon Core is an open-source platform for rapidly deploying machine learning models on Kubernetes. Seldon Deploy is an enterprise subscription service that allows you to work in any language or framework, in the cloud or on-prem, to deploy models at scale. Seldon Alibi is an open-source Python library enabling black-box machine learning model inspection and interpretation.




{kind=link}