 Credit: Gratisography
Credit: Gratisography
NoSQL data stores revolutionised software development by allowing for more flexibility in how data is managed. One of the preeminent NoSQL solutions is MongoDB, a document-oriented data store. We’ll explore what MongoDB is and how it can handle your application requirements in this article.
MongoDB: A document data store
Relational databases store information in strictly regulated tables and columns. MongoDB is a document store, which stores information in collections and documents. The primary difference here is that collections and documents are unstructured, sometimes referred to as schema-less. This means the structure of a MongoDB instance (the collections and documents) is not predefined and flexes to accommodate whatever data is put in it.
A document is a key-value set, which behaves very similar to an object in code like JavaScript: Its structure changes according to the data put in it. This makes coding against a data store like MongoDB easier and more agile than coding against a relational data store. Simply put, the interaction between application code and a document data store feels more natural.
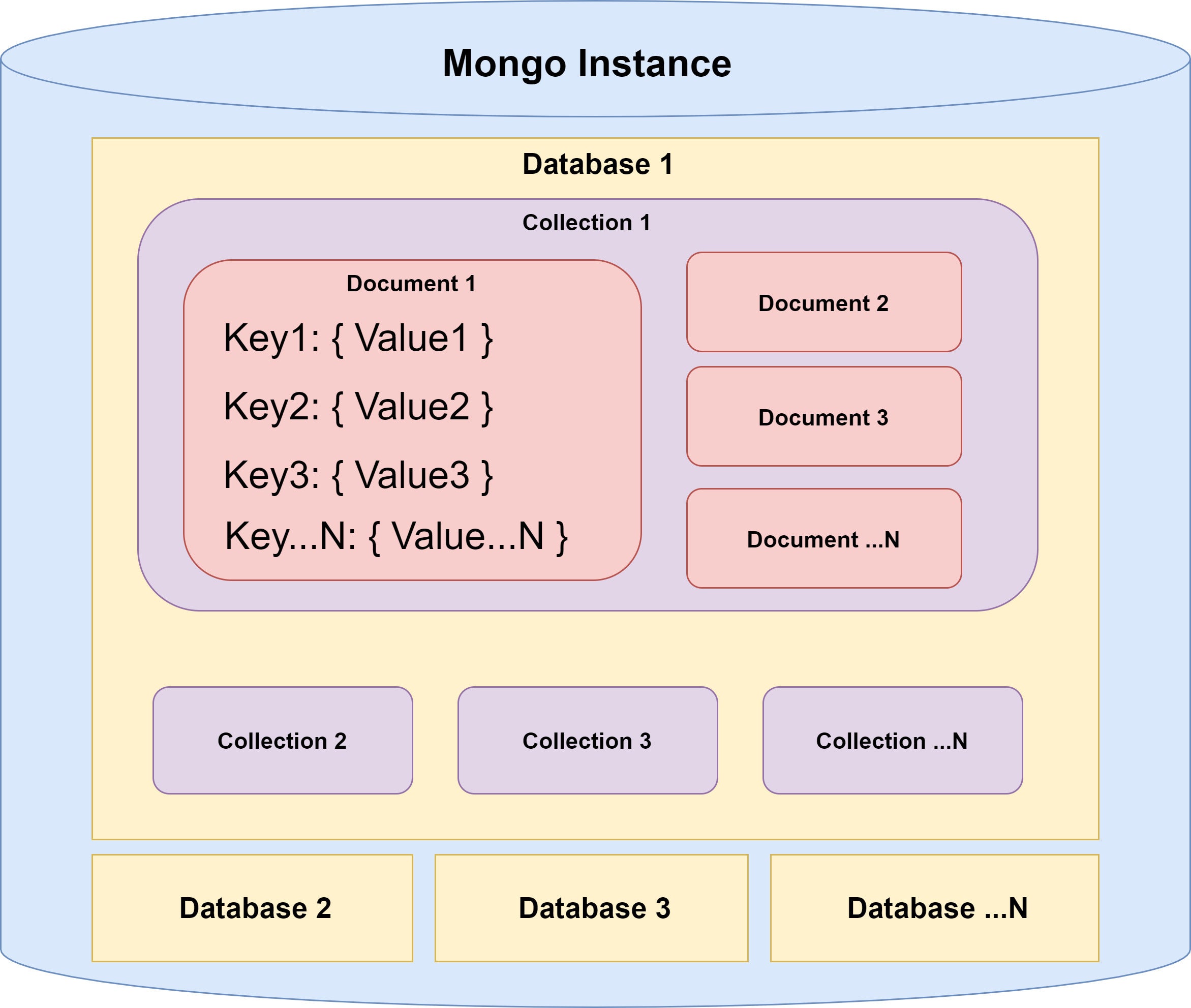
Figure 1 gives a visual look at the structure of MongoDB databases, collections, and documents.
Figure 1. MongoDB document store
 IDG
IDGThe flexibility inherit in this type of data modelling means that data can be handled on a more as-use-demands basis, enabling performance benefits as described here.
To get a concrete understanding of this difference, compare the following two ways to achieve the same task (creating a record and then adding a field from an application), first in a relational database and then in MongoDB.
The steps in a relational database:
# create a database:
CREATE DATABASE menagerie;
# create a table in the database:
USE menagerie; CREATE TABLE pet (name VARCHAR(20));
# connect to the database in app and issue insert:
INSERT INTO pet (name) VALUES ('Friar Tuck');
# add a column:
ALTER TABLE pet ADD type VARCHAR(20));
# update existing record:
UPDATE pet SET type = 'cat' WHERE name = 'Friar Tuck'Now for the same process with MongoDB:
# connect to the database in app and issue insert:
use menagerie; db.pet.insertOne({name:"friar tuck"});
# issue update:
db.pet.updateOne({ name:'friar tuck' }, { $set:{ type: 'cat' } } );From the preceding you can get a sense of how much smoother the development experience can be with MongoDB.
This flexibility of course puts the burden upon the developer to avoid schema bloat. Maintaining a grip on the document structure for large-scale apps is essential.
The ID field in MongoDB
In a relational database, you have the concept of a primary key, and this is often a synthetic ID column (that is to say, a generated value not related to the business data). In MongoDB, every document has an _id field of similar purpose. If you as the developer do not provide an ID when creating the document, one will be auto-generated (as a UUID) by the MongoDB engine.
Like a primary key, the _id field is automatically indexed and must be unique.
Indexing in MongoDB
Indexing in MongoDB behaves similarly to indexing in a relational database: It creates additional data about a document’s field to speed up lookups that rely on that field. MongoDB uses B-Tree indexes.
An index can be created with syntax like so:
db.pet.createIndex( { name: 1 } )The integer in the parameter indicates whether the index is ascending (1) or descending (-1).
Nesting documents in MongoDB
A powerful aspect of the document-oriented structure of MongoDB is that documents can be nested. For example, instead of creating another table to store the address information for the pet document, you could create a nested document, with a structure like Listing 1.
Listing 1. Nested document example
{
"_id": "5cf0029caff5056591b0ce7d",
"name": "Friar Tuck",
"address": {
"street": "Feline Lane",
"city": "Big Sur",
"state": "CA",
"zip": "93920"
},
"type": "cat"
}Denormalisation in MongoDB
Document stores like MongoDB have somewhat limited support for joins (for more information read this article) and there is no concept of a foreign key. Both are a consequence of the dynamic nature of the data structure. Data modelling in MongoDB tends towards denormalisation, that is, duplicating data in the documents, instead of strictly keeping data in table silos. This improves the speed of lookups at the cost of increased data consistency maintenance.
Denormalisation is not a requirement, but more of a tendency when using document-oriented databases. This is because of the improved ability to deal with complex nested records, as opposed to the SQL tendency to keep data normalised (i.e., not duplicated) into specific, single-value columns.
MongoDB query language
The query language in MongoDB is JSON-oriented, just like the document structure. This makes for a very powerful and expressive syntax that can handle even complex nested documents.
For example, you could query our theoretical database for all cats by issuing db.pet.find({ "type" : "cat" }) or all cats in California with db.pet.find({ "type" : "cat", "address.state": "CA" }). Notice that the query language traverses the nested address document.
MongoDB update syntax
MongoDB's alter syntax also uses a JSON-like format, where the $set keyword indicates what field will change, to what value. The set object supports nested documents via the dot notation, as in Listing 2, where you change the zip code for the cat named "Friar Tuck.
Listing 2. Updating a nested document
db.people.update(
{
"type": "cat",
"name": "Friar Tuck"
},
{
$set: {
"address.zip": "86004"
}
}
)You can see from Listing 2 that the update syntax is every bit as powerful — in fact more powerful — than the SQL equivalent.
MongoDB cloud and deployment options
MongoDB is designed for scalability and distributed deployments. It is fully capable of handling web-scale workloads.
MongoDB the company offers a multicloud database clustering solution in MongoDB Atlas. MongoDB Atlas acts like a managed database that can span different cloud platforms, and includes enterprise features like monitoring and fault tolerance.
You get an indication of MongoDB’s importance in that AWS’s Amazon DocumentDB offering includes MongoDB compatibility as a chief selling point. Microsoft’s Azure Cosmos DB follows a similar pattern with MongoDB API support.
High availability in MongoDB
MongoDB supports replica sets for high availability. The core idea is that data is written once to a main instance, then duplicated to secondary stores for reads. Learn more about replication in MongoDB here.
The bottom line is that MongoDB is a leading NoSQL solution that delivers on the promise of flexible-schema data stores. Advanced drivers are available for pretty much every programming language, and you can draw on a multitude of deployment options as well.
For more details on using MongoDB, see this article on using MongoDB with Node.js. You can learn about other NoSQL options and how to choose among them here.



