How to choose a cloud serverless platform
- 12 April, 2021 16:15
Running a server farm in the cloud at full capacity 24/7 can be awfully expensive. What if you could turn off most of the capacity when it isn’t needed? Taking this idea to its logical conclusion, what if you could bring up your servers on-demand when they are needed, and only provide enough capacity to handle the load?
Enter serverless computing. Serverless computing is an execution model for the cloud in which a cloud provider dynamically allocates—and then charges the user for—only the compute resources and storage needed to execute a particular piece of code.
In other words, serverless computing is on-demand, pay-as-you-go, back-end computing. When a request comes in to a serverless endpoint, the back end either reuses an existing “hot” endpoint that already contains the correct code, or allocates and customises a resource from a pool, or instantiates and customises a new endpoint. The infrastructure will typically run as many instances as needed to handle the incoming requests, and release any idle instances after a cooling-off period.
“Serverless” is of course a misnomer. The model does use servers, although the user doesn’t have to manage them. The container or other resource that runs the serverless code is typically running in a cloud, but may also run at an edge point of presence.
Function as a service (FaaS) describes many serverless architectures. In FaaS, the user writes the code for a function, and the infrastructure takes care of providing the runtime environment, loading and running the code, and controlling the runtime lifecycle. A FaaS module can integrate with webhooks, HTTP requests, streams, storage buckets, databases, and other building blocks to create a serverless application.
Serverless computing pitfalls
As attractive as serverless computing can be—and people have cut their cloud spending by over 60 per cent by switching to serverless—there are several potential issues you may have to address. The most common problem is cold starts.
If there are no “hot” endpoints available when a request comes in, then the infrastructure needs to instantiate a new container and initialise it with your code. Instantiation can take several seconds, which is a very long time for a service that’s supposed to respond in single-digit milliseconds. That’s a cold start, and you should avoid it. The lag time can be even worse if you have an architecture in which many serverless services are chained, and all have gone cold.
There are several ways to avoid cold starts. One is to use keep-alive pings, although that will increase the run time used, and therefore the cost. Another is to use a lighter-weight architecture than containers in the serverless infrastructure. A third tactic is to start the runtime process as soon as a client request begins its security handshake with the endpoint, rather than waiting for the connection to be fully established. Still another tactic is to always keep a container “warm” and ready to go through the cloud’s scaling configuration.
A second problem that can affect serverless is throttling. For the sake of cost containment, many services have limits on the number of serverless instances that they can use. In a high-traffic period, the number of instances can hit their limit, and responses to additional incoming requests may be delayed or even fail. Throttling can be fixed by carefully tuning the limits to cover legitimate peak usage without allowing runaway usage from a denial-of-service attack or a bug in another part of the system.
A third problem with the serverless architecture is that the storage layer might not be able to handle peak traffic, and may back up the running serverless processes even though there are plenty of instances available. One solution to that problem is to use memory-resident caches or queues that can absorb the data from a peak and then dribble it out to the database as quickly as the database can commit the data to disk.
A lack of monitoring and debugging tools can contribute to all of these issues and make them harder to diagnose.
You’ll notice that I didn’t list “vendor lock-in” as a pitfall. As you’ll see, that’s more of a trade-off than a real problem.
AWS Lambda and related services
AWS Lambda is a FaaS offering. You might think of AWS Lambda as Amazon’s only serverless product, but you’d be wrong. AWS Lambda is currently one of more than a dozen AWS serverless products. You also might think that AWS Lambda (2014) was the first FaaS service, but it was preceded by Zimki (2006), Google App Engine (2008), and PiCloud (2010).
AWS Lambda supports stateless function code written in Python, Node.js, Ruby, Java, C#, PowerShell, and Go. Lambda functions run in response to events, such as object uploads to Amazon S3, Amazon SNS notifications, or API actions. Lambda functions automatically receive a 500 MB temporary scratch directory, and may use Amazon S3, Amazon DynamoDB, or another internet-available storage service for persistent state. A Lambda function may launch processes using any language supported by Amazon Linux, and may call libraries. A Lambda function may run in any AWS region.
Several of the other AWS serverless products are worth noting. Lambda@Edge allows you to run Lambda functions at more than 200 AWS Edge locations in response to Amazon CloudFront content delivery network events. Amazon DynamoDB is a fast and flexible key-value and document database service with consistent, single-digit millisecond latency at scale. And Amazon Kinesis is a platform for streaming data on AWS. You can also run Lambda functions on local, connected devices (such as controllers for IoT) with AWS Greengrass.
The open source AWS Serverless Application Model (AWS SAM) can model and deploy your serverless applications and services. In addition to SAM, AWS Lambda supports eight open source and third-party frameworks.
The AWS Serverless Application Repository lets you find and reuse serverless applications and application components for a variety of use cases. You can use Amazon CloudWatch to monitor your serverless applications and AWS X-Ray to analyse and debug them. Finally, AWS Lambda recently announced a preview of Lambda Extensions, a new way to easily integrate Lambda with monitoring, observability, security, and governance tools.
Microsoft Azure Functions
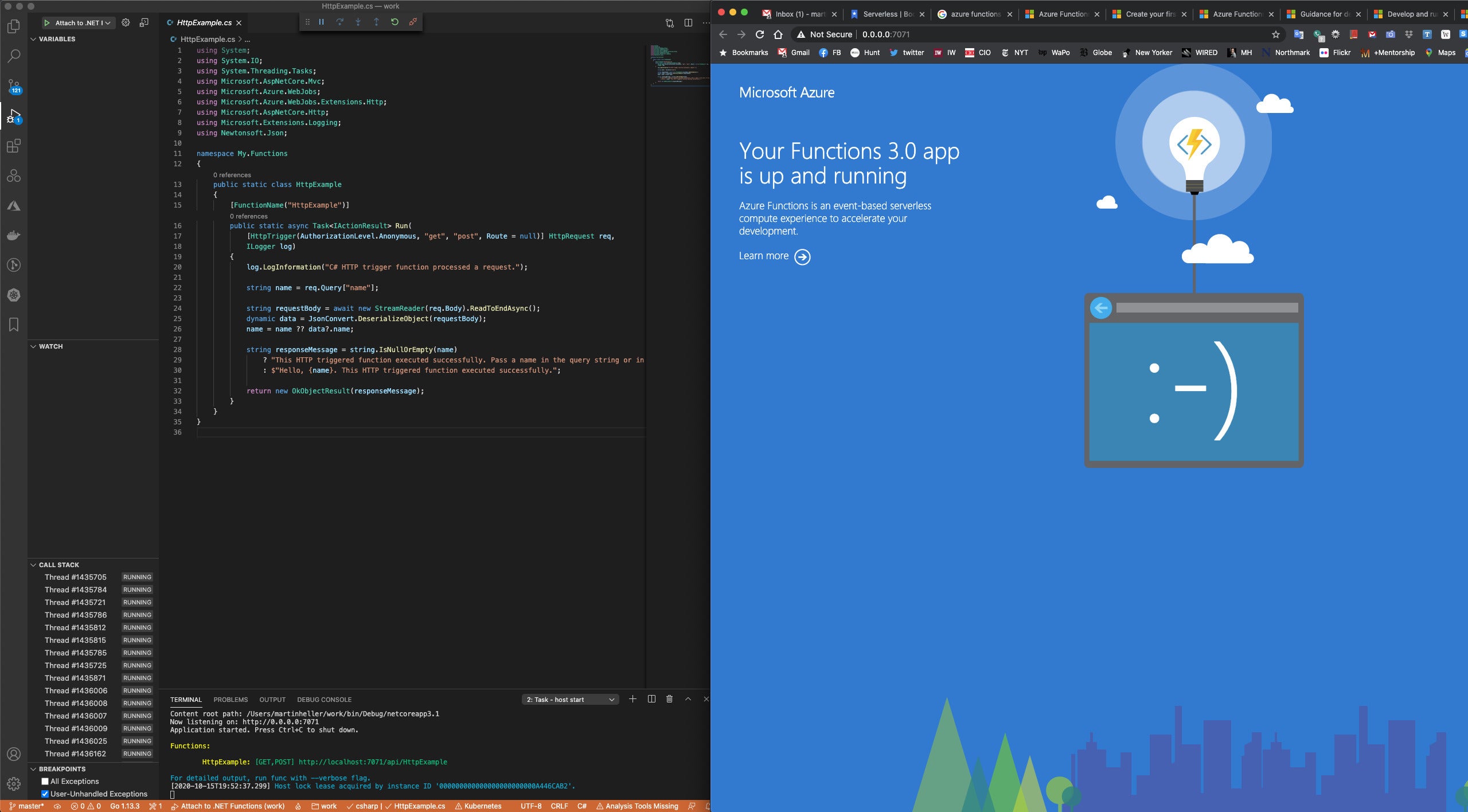
Microsoft Azure Functions is an event-driven serverless compute platform that can also solve complex orchestration problems. You can build and debug Azure Functions locally without additional setup, deploy and operate at scale in the cloud, and integrate services using triggers and bindings.
You can code Azure Functions in C#, F#, Java, JavaScript (Node.js), PowerShell, or Python. Any single Azure Functions app can use only one of the above. You can develop Azure Functions locally in Visual Studio, Visual Studio Code (see screenshot below), IntelliJ, Eclipse, and the Azure Functions Core Tools. Or you can edit small Azure Functions directly in the Azure portal.
Durable Functions is an extension of Azure Functions that lets you write stateful functions in a serverless compute environment. The extension lets you define stateful workflows by writing orchestrator functions and stateful entities by writing entity functions using the Azure Functions programming model.
Triggers are what cause a function to run. A trigger defines how a function is invoked, and a function must have exactly one trigger. Triggers have associated data, which is often provided as the payload of the function.
Binding to a function is a way of declaratively connecting another resource to the function; bindings may be connected as input bindings, output bindings, or both. Data from bindings is provided to the function as parameters.
 IDG
IDGGoogle Cloud Functions
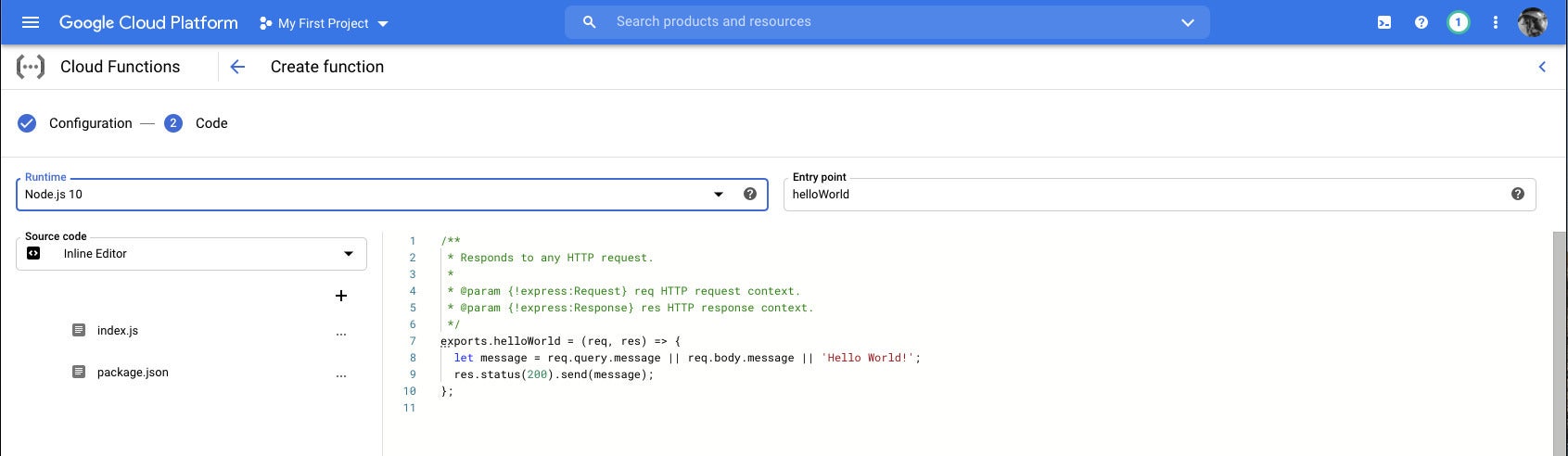
Google Cloud Functions is a scalable pay-as-you-go FaaS platform. It has integrated monitoring, logging, and debugging capability, built-in security at the role and per-function levels, and key networking capabilities for hybrid cloud and multicloud scenarios. It lets you connect to Google Cloud or third-party cloud services via triggers to streamline challenging orchestration problems.
Google Cloud Functions supports code in Go, Java, Node.js (see screenshot below), and Python. Cloud Functions support HTTP requests using common HTTP request methods such as GET, PUT, POST, DELETE, and OPTIONS, as well as background functions to handle events from your cloud infrastructure. You can use Cloud Build or another CI/CD platform for automatic testing and deployment of Cloud Functions, in conjunction with a source code repository such as GitHub, Bitbucket, or Cloud Source Repositories. You can also develop and deploy Cloud Functions from your local machine.
 IDG
IDGIBM Cloud Functions
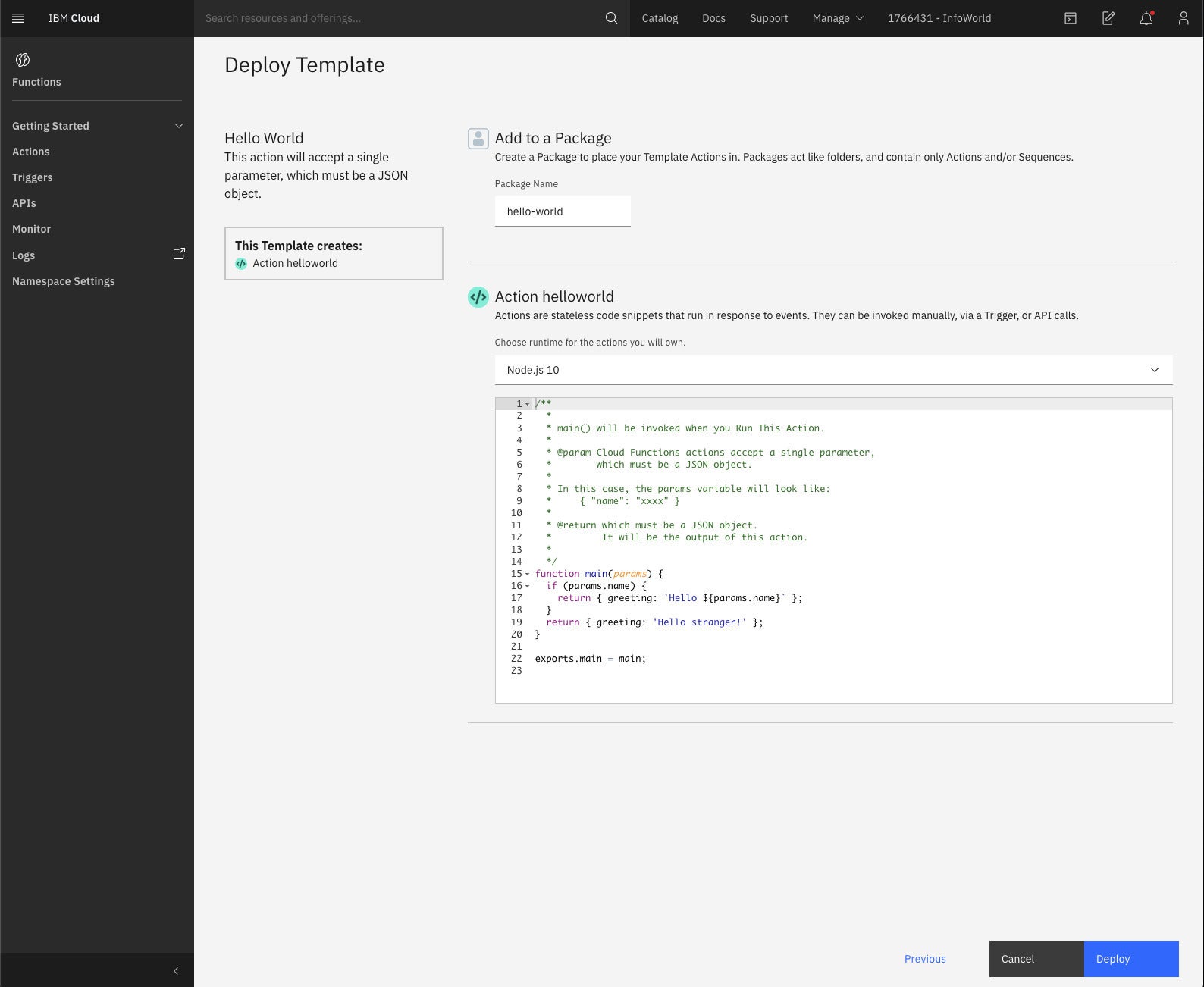
Based on Apache OpenWhisk, IBM Cloud Functions is a polyglot, functions-as-a-service programming platform for developing lightweight code that executes and scales on demand. You can develop IBM Cloud Functions in Node.js (see screenshot below), Python, Swift, and PHP. IBM touts the integration between Cloud Functions and Watson APIs within the event-trigger-action workflow, to make cognitive analysis of application data part of your serverless workflows.
 IDG
IDGOracle Cloud Functions and the Fn Project
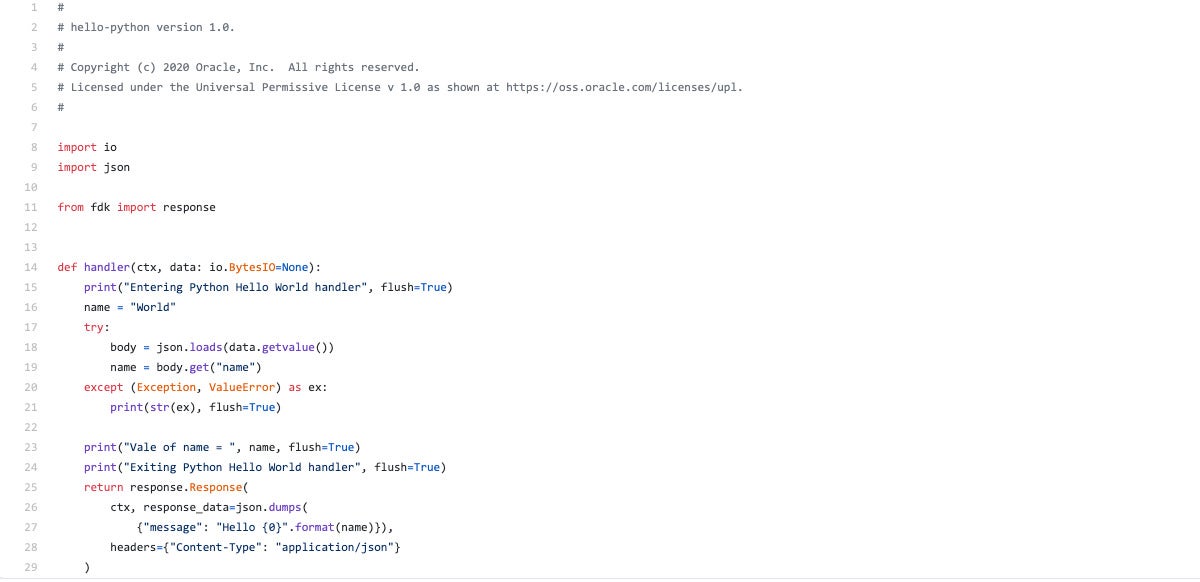
Oracle Cloud Functions is a serverless platform that lets developers create, run, and scale applications without managing any infrastructure. Functions integrate with Oracle Cloud Infrastructure, platform services, and SaaS applications. Because Oracle Cloud Functions is based on the open source Fn Project, developers can create applications that can be ported to other cloud and on-premises environments. Oracle Cloud Functions support code in Python (see screenshot below), Go, Java, Ruby, and Node.js.
 IDG
IDGCloudflare Workers
Cloudflare is an edge network best known for protecting websites from distributed denial of service (DDoS) attacks. Cloudflare Workers let you deploy serverless code to Cloudflare’s global edge network, where they run in V8 Isolates, which have much lower overhead than containers or virtual machines. You can write Cloudflare Workers in JavaScript (see screenshot below), Rust, C, C++, Python, or Kotlin.
Cloudflare Workers don’t suffer from cold start issues as much as most other serverless frameworks. V8 Isolates can warm up in less than five milliseconds. In addition, Cloudflare starts loading a worker in response to the initial TLS handshake, which typically means that the effective cold start overhead goes away completely, as the load time is less than the site latency in most cases.
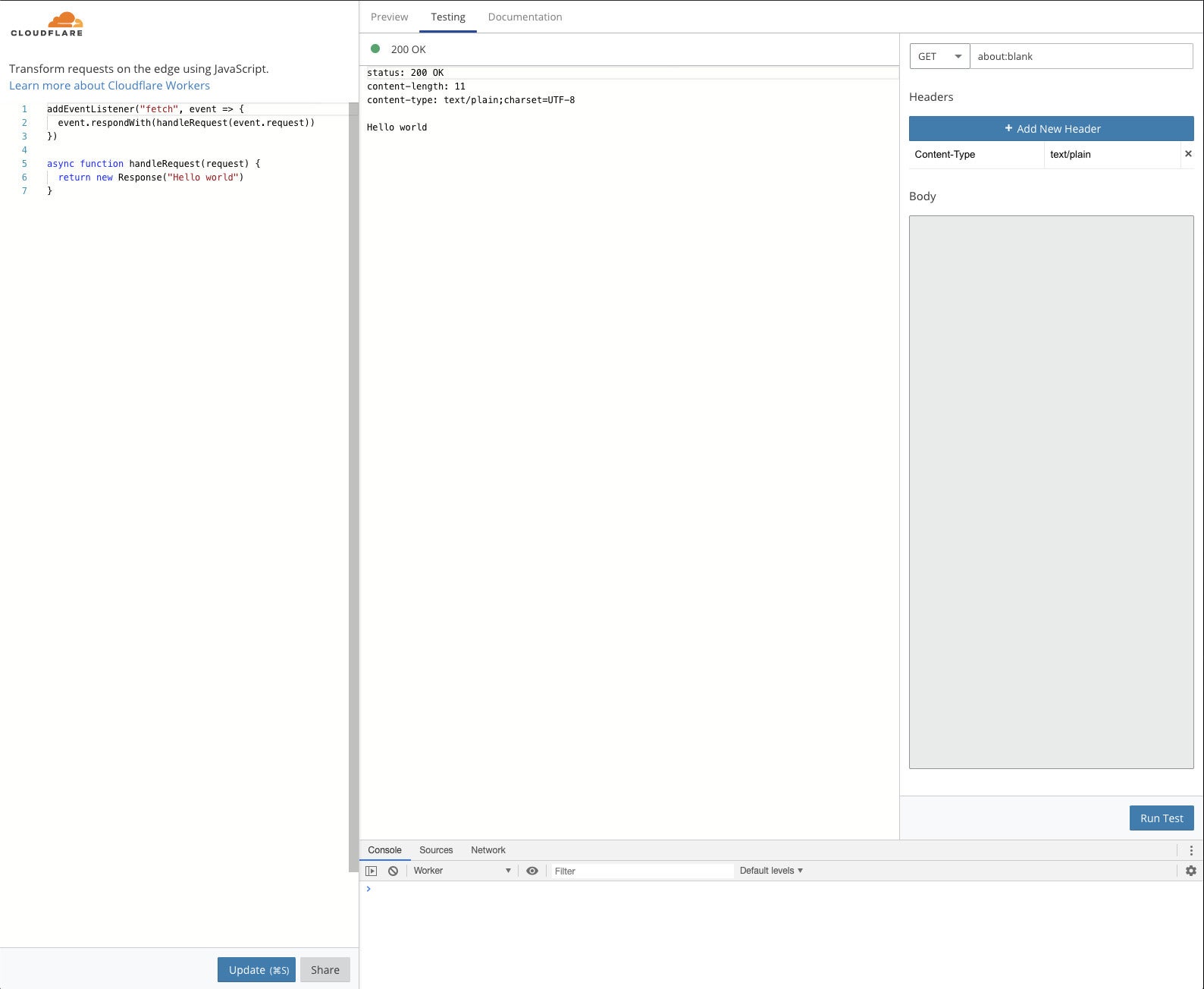 IDG
IDGServerless Framework
Serverless Framework is one way to avoid vendor lock-in with functions-as-a-service, at least partially, by generating function code locally. Under the hood, the Serverless Framework CLI deploys your code to a FaaS platform such as AWS Lambda, Microsoft Azure Functions, Google Cloud Functions, Apache OpenWhisk, or Cloudflare Workers, or to a Kubernetes-based solution such as Kubeless or Knative. You can also test locally. On the other hand, many of the Serverless Framework service templates are specific to a particular cloud provider and language, such as AWS Lambda and Node.js (see screenshot below).
Serverless Components are built around higher-order use cases (e.g. a website, blog, payment system, image service). A plug-in is custom JavaScript code that creates new commands or extends existing commands within the Serverless Framework.
Serverless Framework Open Source supports code in Node.js, Python, Java, Go, C#, Ruby, Swift, Kotlin, PHP, Scala, and more. Serverless Framework Pro provides the tools you need to manage the full serverless application lifecycle including CI/CD, monitoring, and troubleshooting.
 IDG
IDGRead more on the next page...
Page Break
Apache OpenWhisk
OpenWhisk is an open source serverless functions platform for building cloud applications. OpenWhisk offers a rich programming model for creating serverless APIs from functions, composing functions into serverless workflows, and connecting events to functions using rules and triggers.
You can run an OpenWhisk stack locally, or deploy it to a Kubernetes cluster, either one of your own or a managed Kubernetes cluster from a public cloud provider, or use a cloud provider that fully supports OpenWhisk, such as IBM Cloud. OpenWhisk currently supports code written in Ballerina, Go, Java, JavaScript (see screenshot below), PHP, Python, Ruby, Rust, Swift, and .NET Core; you can also supply your own Docker container.
The OpenWhisk project includes a number of developer tools. These include the wsk command line interface to easily create, run, and manage OpenWhisk entities; wskdeploy to help deploy and manage all your OpenWhisk Packages, Actions, Triggers, Rules, and APIs from a single command using an application manifest; the OpenWhisk REST API; and OpenWhisk API clients in JavaScript and Go.
 IDG
IDGFission
Fission is an open source serverless framework for Kubernetes with a focus on developer productivity and high performance. Fission operates on just the code: Docker and Kubernetes are abstracted away under normal operation, though you can use both to extend Fission if you want to.
Fission is extensible to any language. The core is written in Go, and language-specific parts are isolated in something called environments. Fission currently supports functions in Node.js, Python, Ruby, Go, PHP, and Bash, as well as any Linux executable.
Fission maintains a pool of “warm” containers that each contain a small dynamic loader. When a function is first called, i.e. “cold-started,” a running container is chosen and the function is loaded. This pool is what makes Fission fast. Cold-start latencies are typically about 100 milliseconds.
Knative
Knative, created by Google with contributions from more than 50 different companies, delivers an essential set of components to build and run serverless applications on Kubernetes. Knative components focus on solving mundane but difficult tasks such as deploying a container, routing and managing traffic with blue/green deployment, scaling automatically and sizing workloads based on demand, and binding running services to eventing ecosystems. The Google Cloud Run service is built from Knative.
Kubeless
Kubeless is an open source Kubernetes-native serverless framework designed for deployment on top of a Kubernetes cluster, and to take advantage of Kubernetes primitives. Kubeless reproduces much of the functionality of AWS Lambda, Microsoft Azure Functions, and Google Cloud Functions. You can write Kubeless functions in Python, Node.js, Ruby, PHP, Golang, .NET, and Ballerina. Kubeless event triggers use the Kafka messaging system and HTTP events.
Kubeless uses a Kubernetes Custom Resource Definition to be able to create functions as custom Kubernetes resources. It then runs an in-cluster controller that watches these custom resources and launches runtimes on-demand. The controller dynamically injects the code of your functions into the runtimes and makes them available over HTTP or via a publish/subscribe mechanism.
OpenFaaS
OpenFaaS is an open source serverless framework for Kubernetes with the tag line “Serverless functions made simple.” OpenFaaS is part of the “PLONK” stack of cloud native technologies: Prometheus (monitoring system and time series database), Linkerd (service mesh), OpenFaaS, NATS (secure messaging and streaming), and Kubernetes. You can use OpenFaaS to deploy event-driven functions and microservices to Kubernetes using its Template Store or a Dockerfile.
How to choose a cloud serverless platform
With all those options, how can you choose just one? As with almost all questions of software architecture, it depends.
To begin with, you should evaluate your existing software estate and your goals. An organisation that is starting with legacy applications written in Cobol and running on in-house mainframes has a very different path to travel than an organisation that has an extensive cloud software estate.
For organisations with a cloud estate, it’s worth making a list of your deployments, the clouds they use, and which availability zones. It’s also worth understanding the locations of your customers and users, and the usage patterns for your services.
For example, an application that is used 24/7 at a consistent load level isn’t likely to be a good candidate for serverless deployment: A properly sized server, VM, or cluster of containers might be cheaper and easier to manage. On the other hand, an application that is used at irregular intervals and widely varying scales and is triggered by an important action (such as a source code check-in) might be a perfect candidate for a serverless architecture.
A service with low latency requirements that is used all over the world might be a good candidate for deployment at many availability zones or edge points of presence. A service used only in Washington, DC, could be deployed in a single availability zone in Virginia.
A company that has experience with Kubernetes might want to consider one of the open-source serverless platforms that deploy to Kubernetes. An organisation lacking in Kubernetes experience might be better off deploying to a native cloud FaaS infrastructure, whether or not the framework is open source, such as the Serverless Framework, or proprietary, such as AWS Lambda, Google Cloud Functions, or Azure Functions.
If the serverless application you’re building depends on a cloud database or streaming service, then you should consider deploying them on the same cloud to minimise the intra-application latencies. That doesn’t constrain your choice of framework too much. For example, an application that has a Google Cloud Bigtable data store can have its serverless component in Google Cloud Functions, Google Cloud Run, Serverless Framework, OpenWhisk, Kubeless, OpenFaaS, Fission, or Knative, and still likely show a minimum latency.
In many cases your application will be the same or similar to common use cases. It’s worth checking the examples and libraries for the serverless platforms that you’re considering to see if there’s a reference architecture that will do the job for you. It’s not that most functions as a service require writing a lot of code: Rather, code reuse for FaaS takes advantage of well-tested, proven architectures and avoids the need to do a lot of debugging.