3 reasons why centralising data is a bad idea
- 23 June, 2021 17:30

Microservice architectures are a common model for modern applications and systems. They have a specific characteristic of splitting the business responsibility of a large application into distinct, separate components that can be independently developed, managed, operated and scaled.
Microservice architectures provide an effective model for scaling the application itself, allowing larger and more disjointed development teams to work independently on their parts, while still participating in a large application build.
In a typical microservice architecture, individual services are created that encompass a specific subset of business logic. When connected with one another, the entire set of microservices forms a complete, large-scale application, containing the complete business logic.
This model is great for the code, but what about the data? Often, companies that create individual services for specific business logic feel the need to put all the application data into a single, centralised datastore. The idea is to ensure all the data is available for each service that might need it. Managing a single datastore is easy and convenient, and the data modelling can be consistent for the entire application to use, independent of the service that is using it.
Don’t do this. Here are three reasons why centralising your data is a bad idea.
Centralised data is hard to scale
When the data for your entire application is in a single centralised datastore, then as your application grows you must scale the entire datastore to meet the needs of all the services in your application. This is shown in the left side of Figure 1. If you use a separate datastore for each service, only the services that have increased demand need to scale, and the database being scaled is a smaller database. This is shown in the right side of Figure 1.
It’s a lot easier to scale a small database bigger than it is to scale a large database even larger.
 IDG
IDG
Figure 1. Partitioning data by services simplifies scaling.
Centralised data is hard to partition later
A common thought process for developers of a newly created app is, “I don’t need to worry about scaling now; I can worry about it when I need it later.” This viewpoint, while common, is a recipe for scaling issues at the most inopportune time. Just as your application gets popular, you have to worry about rethinking architectural decisions simply to meet incremental customer demand.
One common architectural change that comes up is the need to split your datastore into smaller datastores. The problem is, this is much easier to do when the application is first created than it is later in the application’s life cycle. When the application has been around for a few years, and all parts of the application have access to all parts of the data, it becomes very difficult to determine what parts of the dataset can be split into a separate datastore without requiring a major rewrite of the code that uses the data. Even simple questions become difficult. Which services are using the Profiles table? Are there any services that need both the Systems and the Projects tables?
And, even worse, is there any service that performs a join using both tables? What is it used for? Where is that done in the code? How can we refactor that change?
The longer a dataset stays in a single datastore, the harder it is to separate that datastore into smaller segments later.
By separating data into separate datastores by functionality, you avoid issues related to separating data from joined tables later, and you reduce the possibility for unexpected correlations between the data to exist in your code.
Centralised data makes data ownership impossible
One of the big advantages of dividing data into multiple services is the ability to divide application ownership into distinct and separable pieces. Application ownership by individual development teams is a core tenet of modern application development that promotes better organisational scaling and improved responsiveness to problems when they occur. This ownership model is discussed in the Single Team Oriented Service Architecture (STOSA) development model.
This model works great when you have a large number of development teams all contributing to a large application, but even smaller applications with smaller teams benefit from this model.
The problem is, for a team to have ownership of a service, they must own both the code and the data for the service. This means one service (Service A) should not directly access the data of another service (Service B). If Service A needs something stored in Service B, it must call a service entry point for Service B, rather than accessing the data directly.
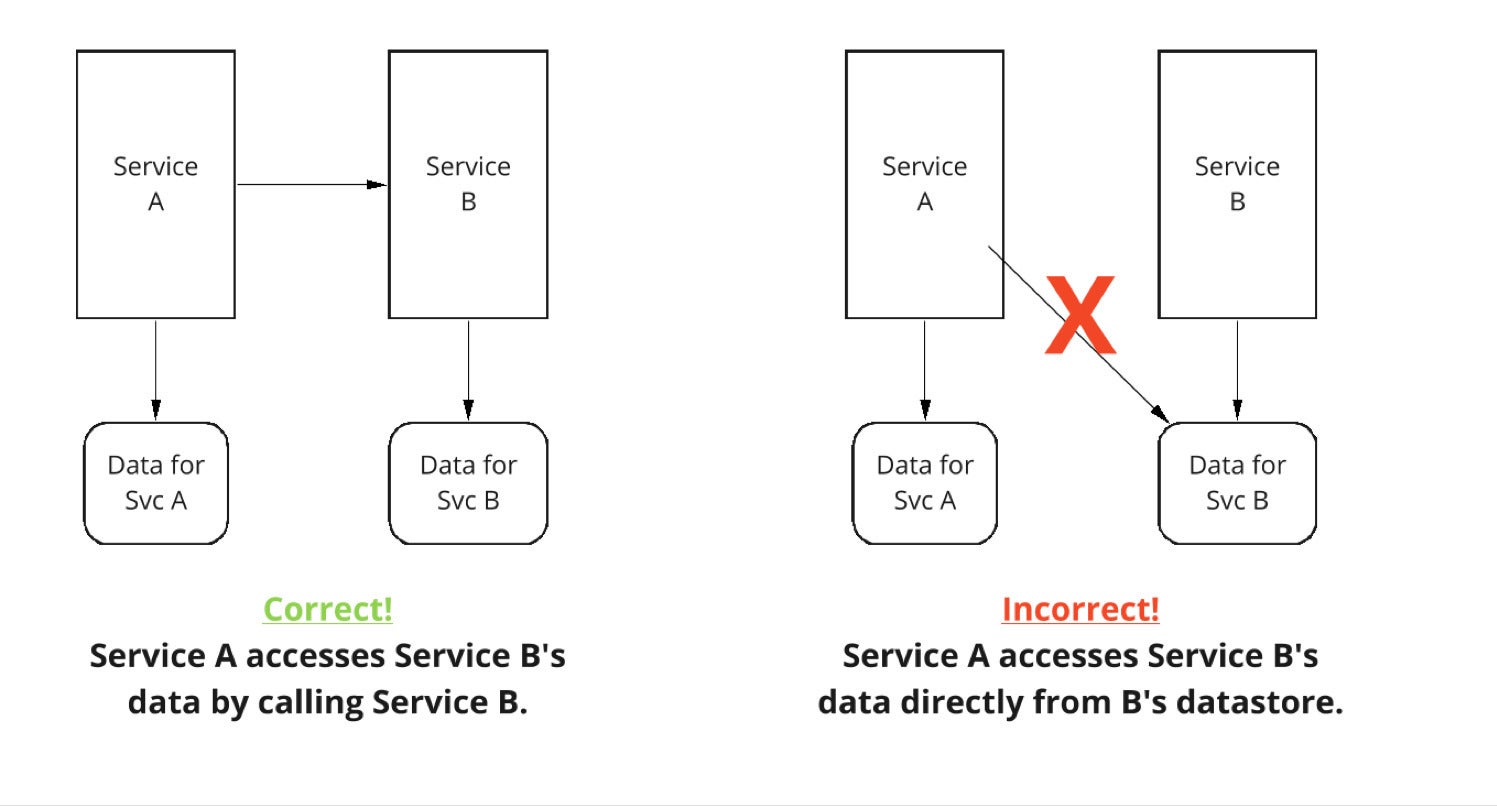 IDG
IDG
Figure 2. Service A should never directly access Service B’s data.
This allows Service B to have complete autonomy over its data, how it’s stored, and how it’s maintained.
So, what’s the alternative? When you construct your service-oriented architecture (SOA), each service should own its own data. The data is part of the service and is incorporated into the service.
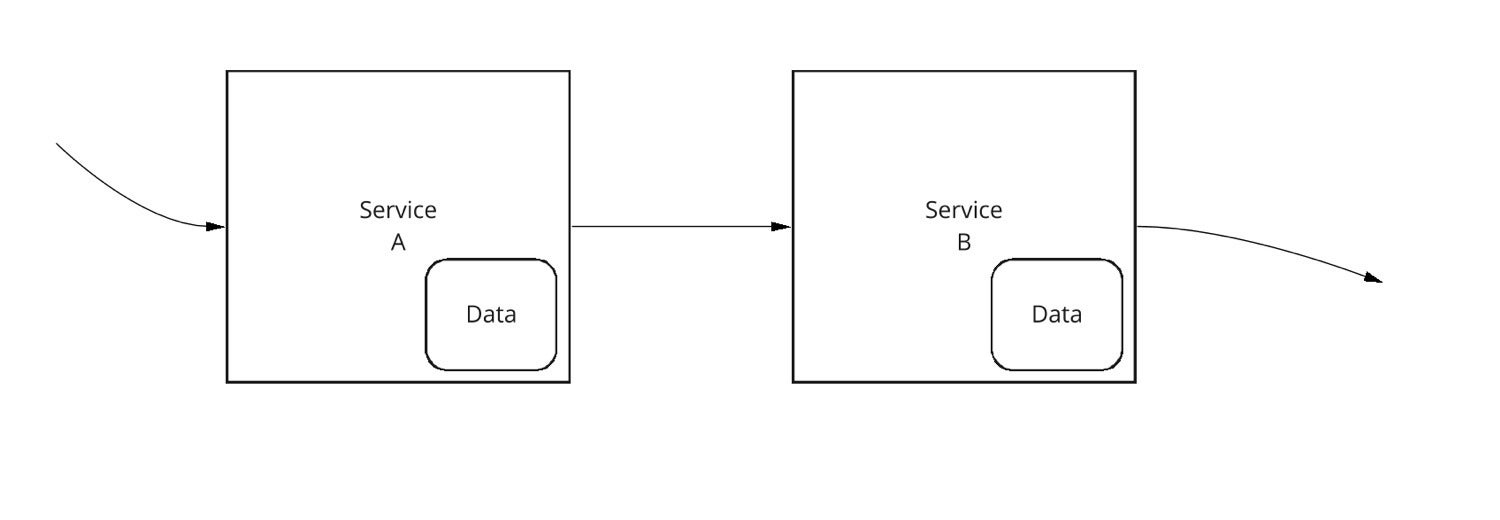 IDG
IDG
Figure 3. Each service has its own data.
That way, the owner of the service can manage the data for that service. If a schema change or other structural change to the data is required, the owner of the service can implement the change without the involvement of any other service owner. As an application (and its services) grows, the service owner can make scaling decisions and data refactoring decisions to handle the increased load and the changed requirements, without any involvement of other service owners.
A question often comes up, what about data that truly needs to be shared between applications? This might be data such as user profile data, or other data commonly used throughout many parts of an application. A tempting, quick solution might be to share only the needed data across multiple services, such as shown in Figure 4. Each service might have its own data, and also have access to the shared data.
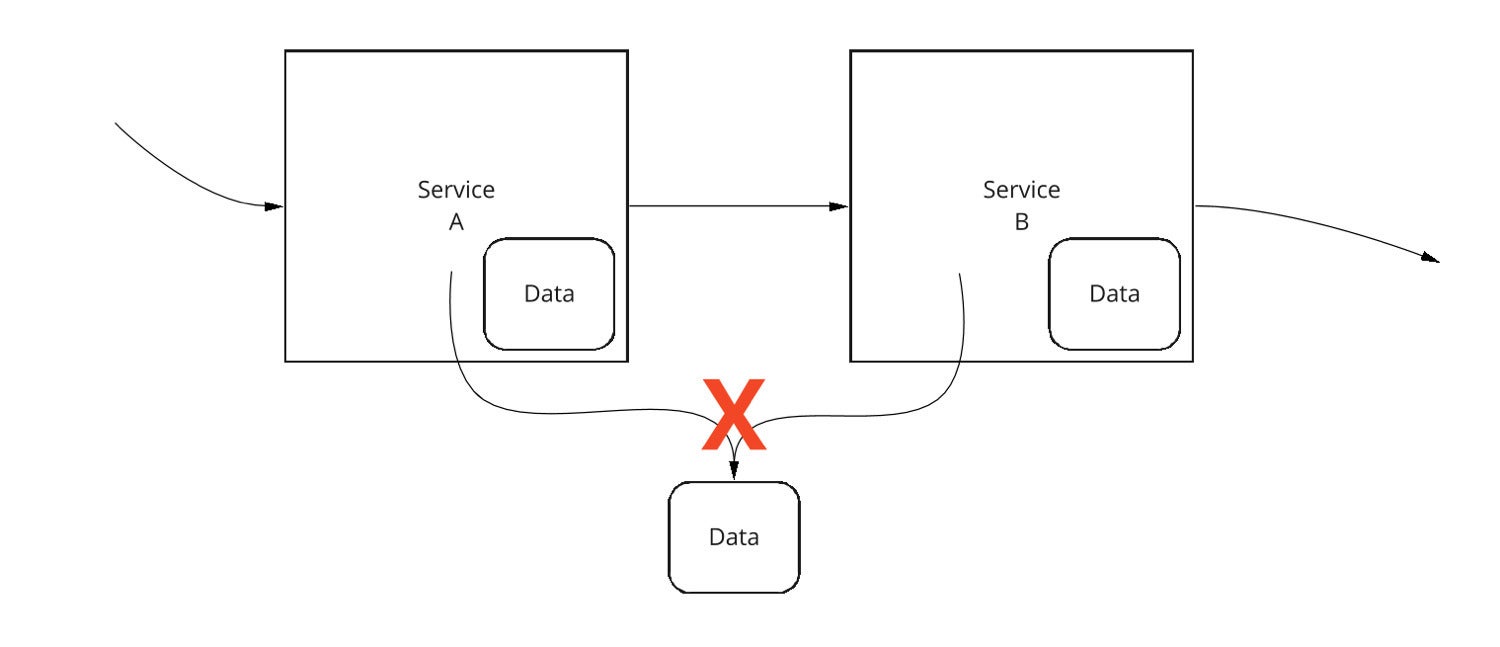 IDG
IDG
Figure 4. Sharing data between services is not recommended.
A better approach is to put the shared data into a new service that is consumed by all other services, shown in Figure 5.
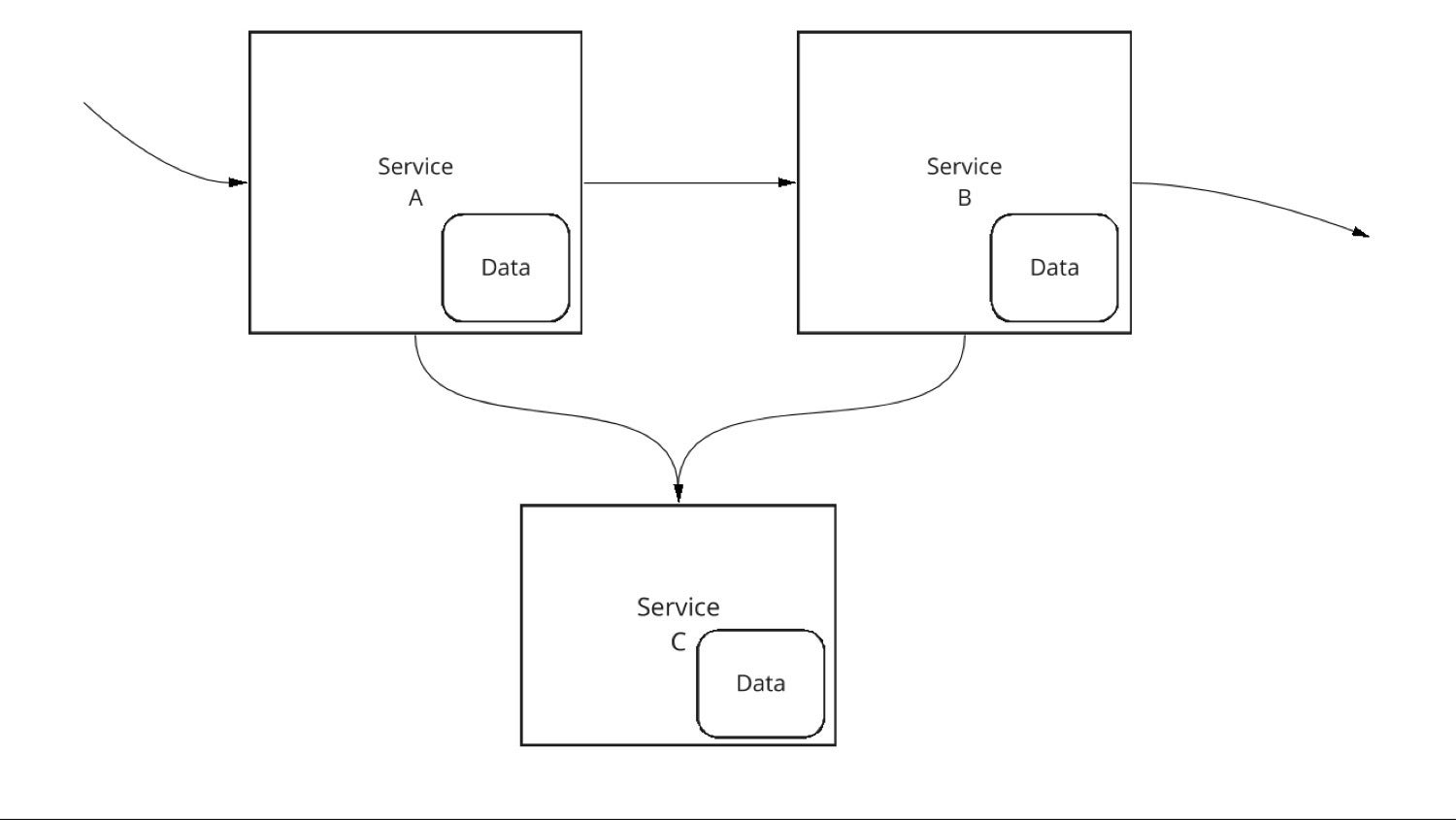 IDG
IDG
Figure 5. Using a service is the proper way to access shared data.
The new service—Service C—should follow STOSA requirements as well. In particular, it should have a single, clear team that owns the service, and hence owns the shared data. If any other service, such as Service A or Service B in this diagram, needs to access the shared data, it must do so via an API provided by Service C. This way, the owner of Service C is the only team responsible for the shared data. They can make appropriate decisions on scaling, refactoring, and updating. As long as they maintain a consistent API for Service A and Service B to use, Service C can make whatever decisions it needs to about updating the data.
This is opposed to Figure 4, where both Service A and Service B access the shared data directly. In this model, no single team can make any decisions about the structure, layout, scaling, or modelling of the data without involving all other teams that access the data directly, thus limiting scalability of the application development process.
Using microservices or other SOA is a great way to manage big development teams working on large applications. But the service architecture must also encompass the data of the application, or true service independence—and hence, true scaling independence of the development organisation—will not be possible.